
Hi TOSA-authors, I took a stab at writing up an addendum to the TOSA specification which I believe would enable compilers and tools to be easily constructed for fixed-rank, dynamically shaped tensor programs of the form that TOSA seems at a level to specify. These definitions represent several years of learnings having implemented similar approaches in MHLO, IREE, and XLA – and encodes the decisions that I wish we had made from the get-go on those projects while the representations were new and unencumbered. There is much more that can be done in this area to enable increasingly dynamic programs, but I believe what I present below to strike the right balance with respect to what TOSA is trying to achieve in its current state, supporting lowerings for common programs, and preserving the simplicity and accessibility of the static form for implementations that are not dynamic.
I further believe that the existing LLVM/MLIR based implementation of TOSA (and the lowerings from TF/TFLite) could be fairly trivially extended to implement this, providing direct tooling for expressing symbolically-shaped tensor programs (and tooling to specialize, etc).
I wrote this in a form intended for evaluation/discussion, not necessarily direct contribution to the Spec. It would need to be reworked and folded into relevant sections of the specification.
For the lawyers: This thread can be considered a “Google Contribution to the TOSA Specification”.
Dynamic Shape Support
In its present form, TOSA defines operations sufficient to represent a wide variety of fixed-rank tensor programs. While this clearly includes fully statically shaped programs (where there are no unknown dimensions in any tensor), it is also useful for the representation to be complete for expressing fixed-rank symbolically shaped programs. History has shown that this is a useful subset (compared to the full generality of a completely rank-unknown representation).
Supporting symbolically shaped programs in detail is left to specific toolchain and compiler implementations. TOSA itself merely seeks to ensure that programs which are otherwise spec-compliant but have unknown, symbolic dimensions are unambiguous in a very direct fashion.
At the present time, there is no requirement that conforming implementations accept programs for execution with unknown, symbolic dimensions, but if they do so, they must do so completely/correctly in conformance with this specification.
Definitions
Fixed-rank
: A tensor whose rank is known. Specific dimensions of the tensor may be unknown.
Static-shaped
: A tensor or program consisting entirely of Fixed-rank tensors (or other primitive, unshaped datatypes) where there are no Dimension Symbols.
Dimension Symbol
: A dimension of a tensor that is unknown. The unknown dimension is uniquely identified by a reference to the tensor, combined with its 0-based offset in the dimension list.
Index Type
: A type sufficient to represent all legal values of a Dimension Symbol. While this can be a more restrictive type, it is assumed that a signed 64-bit integer is sufficient for all implementations.
Dimension Value
: An Index Typed value which represents the explicit quantity that a Dimension Symbol is assumed to take.
Shape Ambiguous
: An operation which, when any of its input or output dimensions are unknown, is ambiguous with respect to its output shape unless if it is parameterized with explicit values for each unknown Dimension Symbol.
Expansion Symbol
: For operations with broadcast semantics, a special symbol which signifies the the dimension expands relative to its broadcast-peers. At present, the only valid Expansion Symbol is the literal 1 dimension in a tensor dimension list. Notably, a generic Dimension Symbol can never be interpreted as an Expansion Symbol in the current spec version.
Approach
A majority of TOSA ops are not Shape Ambiguous. These operations require no further information in the presence of Dimension Symbols and are not discussed in this section, unless if there are specific caveats.
This leaves three categories of ops requiring further definition:
-
Shape Ambiguousoperations: each is outlined here with the additional definitions to make it unambiguous. -
Shape helper operations: the above (and common usage) requires a library of additional shape helper operations in order to be complete. These are specified in this section. Such operations should never exist in a
Static-shapedprogram, and it is assumed that any conforming compiler which accepts symbolically shaped programs can eliminate them if all constraints are known. -
Data Dependent Shaped Operations: A number of TOSA operations are defined such that they require constant (attribute) arguments for shape-impacting behavior. This section does not expand the semantics for these operations and assumes that a future version of the specification will define new operations, which are expected to decay to more primitive form when all symbols are known.
Shape Ambiguous Operations
Typically shape ambiguous operations are made unambiguous by requiring that they accept an additional list of Dimension Values for each Dimension Symbol. The order and any additional interpretation is provided below for each op. These addendums should be added to the overall op description prior to publishing the spec.
RESHAPE operation
If any of the shape dimensions is unknown, then the op must be parameterized with an additional shape_symbols variadic list of Dimension Value corresponding to each Dimension Symbol in the output shape. In this case, the new_shape attribute must have a -1 value for any Dimension Symbol, and all dimensions must be explicit (i.e. rescinds the rule "At most one dimension may be given as-1 to automatically calculate the dimension size).
Data Dependent Shaped Operations
In order to represent more symbolically shaped programs, it is expected that a future version of the specification will need to define several data-dependent variants of ops. Effort should be undertaken to make these not exhibit shape ambiguity and preserve simple transformations to purely static forms as possible.
-
IOTA: Creates linear increasing tensor of numeric values. Will require explicit variadic ofIndexTypefor the range. -
DATA_DEPENDENT_SLICE: Equivalent toSLICEbut takes start and/or sizes dynamically. Extending in this way does not introduce shape ambiguity. -
DATA_DEPENDENT_PAD: Equivalent toPADbut accepts padding as an explicit variadic ofIndexTypequantities forpadding. -
DATA_DEPENDENT_GATHER/DATA_DEPENDENT_SCATTER: Variants ofGATHERandSCATTERwhich accept variadic ofIndexTypequantities for indices. -
DATA_DEPENDENT_CONV2D/DATA_DEPENDENT_CONV3D/DATA_DEPENDENT_DEPTHWISE_CONV2D/DATA_DEPENDENT_TRANSPOSE_CONV2D: Variants of the conv ops which take all parameters as operands instead of compile time constants (pad,stride,dilations). Each should be a variadic ofIndexTypequantities suitable for the specific form.
In general, as the design space permits, new ops should be defined in ways that limit shape ambiguity and accept additional index/dimension arguments as variadic packs of IndexType that correspond to the overall constraints of the operation. Keeping such symbols as simple scalars helps distinguish the types of data dependence and simplifies analysis/compilation, especially for more constrained programs (i.e. as opposed to representing indices/dimensions as tensor values).
Defining operations with data dependent dimensions in this fashion allows straight-forward tooling to be constructed which can fixate Dimension Symbols in the graph, allowing all such data dependent operations to decay to purely static forms, leveraging simple transformations and shape transfer functions.
Shape Helper Operations
A small number of helper operations to allow programs conforming to the above definitions to be represented.
INDEX_CONST
Attributes:
-
value:IndexTypevalue of the constant
Returns: An IndexType value.
GET_DIM
Inputs:
-
input: Thetensorvalue to extract a dimension from.
Attributes:
-
dim_index: The 0-based index of the dimension to extract frominput.
Returns: An IndexType value corresponding to the runtime size of the given dimension (which can either be static or symbolic).
EXTRACT_DIM
Inputs:
-
input: A 1Dtensorof an integer type.
Attributes:
-
dim_index: The 0-based index of the element to extract frominput.
Returns: An IndexType value corresponding to the integer value at input[dim_index]
DIMS_TO_TENSOR
Inputs:
-
dims: Variadic list ofIndexTypedimensions with an arity equal to the rank of the result.
Returns: A 1D tensor of an integer type containing the given list of dims, cast to the specified result element type.
EXPAND_DIMS
Inputs:
-
input: An arbitrary tensor.
Attributes:
-
indices:IndexTypelist of indices in theinputtensor at which point to insert anExpansion Symbol(i.e. static1dim in the present implementation). Must be sorted in increasing order.
Returns:
- A tensor with the same contents as
inputbut with its dimension list expanded by adding a1dim at each location in theinputshape matching a the next value inindices, proceeding left to right through that list.
COLLAPSE_DIMS
Inputs:
-
input: An arbitrary tensor.
Attributes:
-
indices:IndexTypelist of indices in theinputtensor at which point to remove anExpansion Symbol(i.e. static1dim in the present implementation). Must be sorted in increasing order.
Returns:
- A tensor with the same contents as
inputbut with every dimension inindicesremoved, presuming that each is anExpansion Symbol(i.e. static1dim in the present implementation).
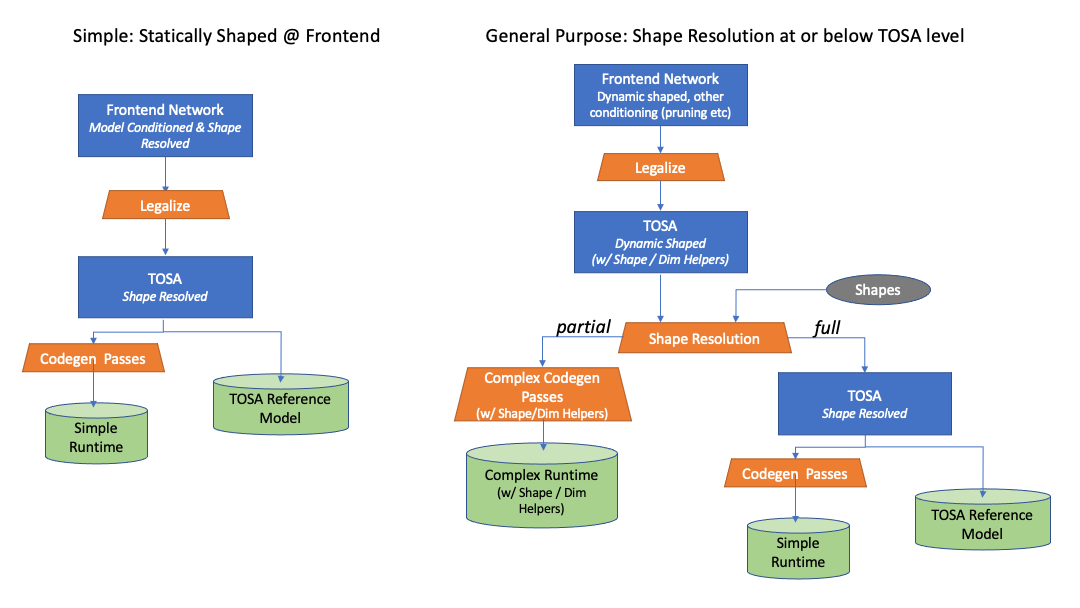
 Yes I think a standard guide would be very useful. Ideally it would be agnostic to a compiler infrastructure but could use LLVM/MLIR for examples. It would also need to define a host-device abstraction to express what run time information is carried to the implementations of the operators as dynamically resolved/broadcasted shapes are known.
Yes I think a standard guide would be very useful. Ideally it would be agnostic to a compiler infrastructure but could use LLVM/MLIR for examples. It would also need to define a host-device abstraction to express what run time information is carried to the implementations of the operators as dynamically resolved/broadcasted shapes are known.